
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | ||||
| 4 | 5 | 6 | 7 | 8 | 9 | 10 |
| 11 | 12 | 13 | 14 | 15 | 16 | 17 |
| 18 | 19 | 20 | 21 | 22 | 23 | 24 |
| 25 | 26 | 27 | 28 | 29 | 30 | 31 |
- cor()
- git오류
- Eclipse
- R프로그래밍
- LIKE검색
- RProgramming
- str()
- 이클립스
- summary()
- querydsl적용하기
- 이중배열
- stepfilter
- queryDSL
- JPA
- R명령어
- 머신러닝
- 한글깨지는문제
- r
- 머신러닝프로세스
- 프로그래머스
- java
- 알고리즘
- Spring
- programmers
- 자바
- DTO사용이유
- git
- Rstudio
- core.autocrlf
- Q타입클래스
- Today
- Total
놀고 싶어요
[R Programming] 머신러닝: 의사결정나무 본문
머신러닝: 의사결정나무
입력데이터에 대해 까다로운 점이 없어 널리 사용되고 있다.
다만, 과적합이 발생하기 쉬워서 보완이 필요할 수도 있는 방법이다.
(과적합: 학습정확도는 높은 반면에 예측정확도가 낮아지는 상황을 말한다.)
Tree 그리기
예제) 대여 건수가 500건이 넘는지 안넘는지?
install.packages("tree")
library(tree)
set.seed(1234)
데이터를 나누기 전, set.seed()라는 함수를 사용하여 결과가 항상 동일할 수 있도록 출발점을 고정
set.seed()함수는 난수를 사용해서 랜덤하게 만드는 기능을 활용하는 모든 경우에 출발점을 고정함으로써 항상 동일한 결과가 나오도록 하는 기능이다.
1234로 값을 고정한 경우, 1234가 아닌 다른 숫자를 사용한 경우, 아예 seed를 사용하지 않았을 떼 어떤 변화가 있는지
실험해보는 것 권장
bike_weather$over_500 <- as.factor(bike_weather$over_500)
levels(bike_weather$over_500) <- c("No", "Yes")
트리를 구성할 때 종속변수에 해당하는 label은 factor라는 형식을 가지고 있어야 한다.
factor 는 범주형이라는 의미로 ‘Yes/No’, ‘남/여’, ‘대/중/소’같이 분류의 기준으로 사용한다는 의미를 담고 있다.
500회가 넘지 않으면 0, 넘으면 1로 사용하던 것을 factor로 변경하여 0은 No, 1은 Yes를 의미하도록 지정해준다.
| as.factor(): factor로 변경해주는 함수 levels(): level을 정해주는 함수 여기서는 levels() 함수를 이용하여 Yes 와 No로 지정해 주었다. |
train_index <- createDataPartition(bike_weather$Time_out, p=.7, list=F)
training <- bike_weather[train_index,]
testing <- bike_weather[-train_index,]Training set와 test set 로 데이터 나누어 준다.
treemod <- tree(over_500 ~ cum_precipitation+humidity+temp+wind, data=training)
treemod <- tree()
의사결정나무를 만들기 위해서 tree라는 함수를 사용해서 학습한다를 의미한다.
over_500를 결과값으로 label이라고 부른다.
cum_precipitation+humidity+temp+wind: +로 연결된 4개의 항목들은 이 라벨을 찾아 구분할 때 사용되는 Feature, 특성값 들이다.
1. tree그리기
plot(treemod)
text(treemod)
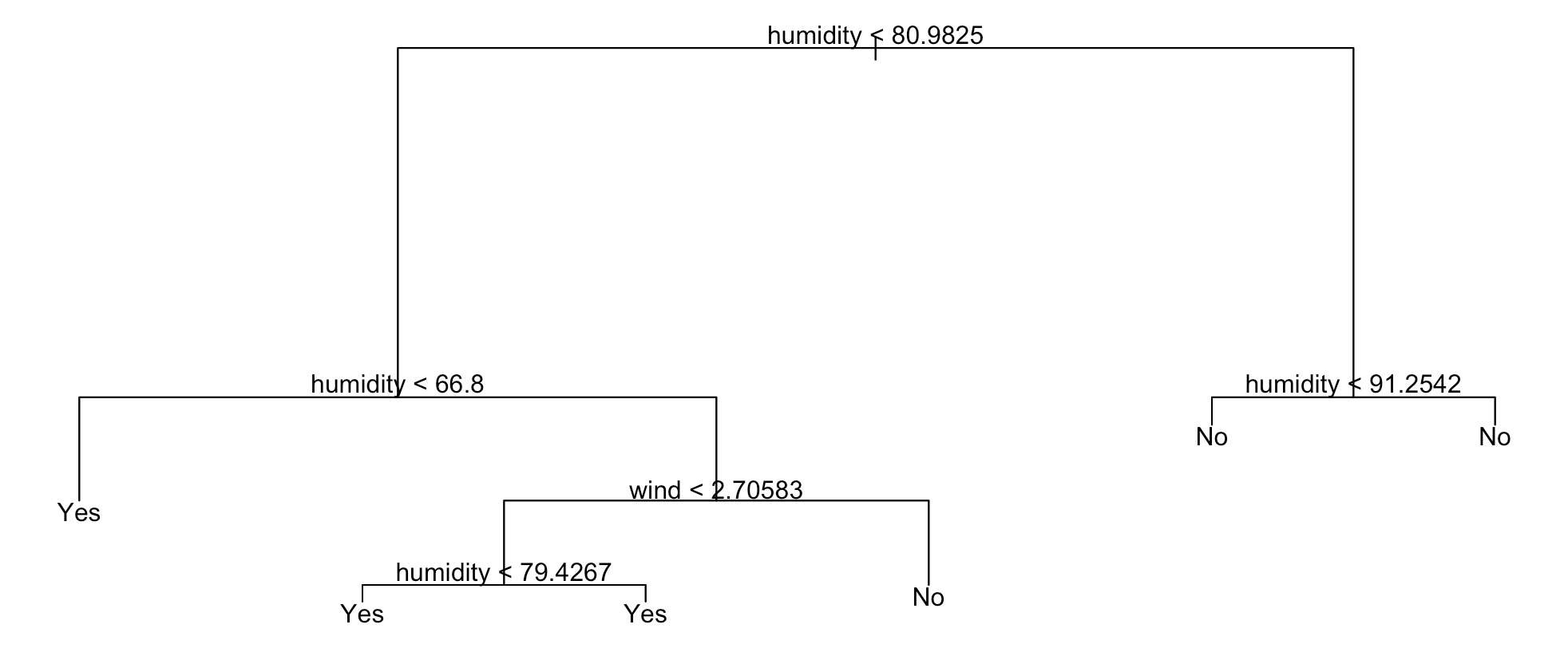
첫 출발점은 제일 위에있는 루트 노드다.
각 노드에는 첫 줄에 분류 기준 항목하고 기준값이 있다. 이런 분류 기준을 Feature(특징)라고 한다.
독립변수의 역할을 하는 값들로 분류 문제를 다룰 때에는 Feature라는 이름으로 주로 불린다.
(예제에서는 cum_precipitation, humidity, temp, wind)
제일 중요한 Feature가 제일 위 루트 노드에 나타난다.
예시에서는 첫번째 선택된 feature는 humidity이고 기준 값은 80.9825가 나왔다.
humidity가 이 값보다 작으면 왼쪽으로 분기하고 같거나 크면 오른쪽으로 분기한다.
예시 의사결정나무는 학습 데이터로 그린 tree이다.
예측할 때는 새로운 데이터를 한 행씩 루트 노드로부터 시작해서 Feature와 기준값을 보고 좌우로 분기해가면서 내려가다 보면 더 이상 내려갈 자녀 세대가 없는 리프 노드에 도달한다. 이 리프노드에 표시된 값을 보고 label을 결정한다.
2. Predict함수를 이용한 예측단계
install.packages('e1071')
library(e1071)
treepred <- predict(treemod, testing, type='class')
confusionMatrix(treepred, testing$over_500, positive = 'Yes')
type=‘class’
predict함수를 이용하여 예측하는데 type은 분류를 의미하는 classification 을 뜻하는 class를 지정해 주었다.
confusionMatrix(treepred, testing$over_500, positive = 'Yes')
그렇게 만들어진 tree예측값 treepred를 정답인 testing 데이터의 over_500하고 함께 confusionMatrix함수에 넣어 다양한 정확도를 계산한다.
3. confusionMatrix함수를 이용한 정확도 계산
confusionMatrix는 혼동 행렬, 혼동표 라고 부르기도 한다.
정확도 계산에 기본이 되는 집계표 이다.
confusionMatrix(treepred, testing$over_500, positive = 'Yes')
마지막 인자로 사용된 positive 는 우리 관심의 기준을 의미한다.
Ex) 불량을 찾는 경우 양품이 아닌 불량품을 얼마나 정확하게 찾는가가 훨씬 중요한 문제가 된다.
우리의 분석 대상이 어느 쪽(Yes/No)인지 알려주면 그 기준으로 정확도를 계산해 주게 된다.

Confusion Matrix and Statistics
제일 첫 부분이 혼동행렬이다.
Reference는 정답이고 Prediction은 이전에 만든 트리를 사용해서 계산 결과 나온 예측값이다.
Accuracy : 0.6842
정확도 Accuracy 는 0.6842로 68%정도 된다.
Sensitivity : 0.8000
Sensitivity는 Recall이라고도 한다. 진짜 Yes 가운데 얼마나 많이 Yes를 찾아냈는가를 의미한다.
0.9로 90%가 된다는 점을 알 수 있다.
Specificity : 0.5556
‘특이도’, 진짜 No가운데 얼마나 No를 찾아냈는가 를 의미한다.
( 답, 예측 No ) / (( 답, 예측 No ) + ( 답은 No 예측은 Yes ))
Pos Pred Value : 0.6667
이 값은 Precision이라는 이름으로 많이 알려져 있는 값이다.
예측에서 Yes라고 한 것이 그 중 얼마나 진짜 Yes를 포함하고 있는가를 측정하는 값
로지스틱 회귀분석의 결과를 평가하던 방법과 비교해보면 결과를 계산한 값이 같게, 비슷하게 나오지만
보여주는 방법과 내용, 명칭이 다르기 때문에 본인에게 좀 더 편리하게 사용하는 방법을 충분히 익히는 것이 좋다.
어느 분석 방법이 좀 더 우위에 있다고 할 수는 없다.
데이터마다 서로 맞는 기법이 달라서 정확도(Accuracy)만 보고 특정한 것이 우위에 있다고 할 수는 없다.
데이터마다 서로 다른 결과, 퍼포먼스를 보여주게 된다. 데이터마다 궁합이 맞는 기법이 있을 수 있다.
그래서 대부분 한 가지 기법을 선택하고 그것만 집중하는 대신에 여러 가지 기법으로 작업을 해보고 더 우수한 결과를 보이는 기법을 선택하는 일종의 trial & error 방식을 사용한다.
트리기법은 주어진 학습 데이터의 특성에 지나치게 의존하는 결과가 나오기 때문에 새로운 데이터를 가져와서 예측하고 판정해본다면 학습정확도는 상당히 훌륭했음에도 예측 정확도는 만족스럽지 않은 결과를 초래할 수 있다.
또한 항상 최적의 모델을 찾아주지 않는다. 이런 이유로 의사결정나무의 약점을 보완하는 다양한 고급 기법들이 개발되어 있다.
최적 보장은 하지 않는다. 적절할 때 멈추는 것이 더 좋은 예측 결과를 보이며, 경우에 따라 다르다.
의사결정나무는 직관적이고 이해하기 쉬우며 데이터에 대한 제약이 적다.
데이터 안에 정답이 있어 입력값과 정답을 비교하면서 수식을 찾거나 확률을 찾는 방식으로 수치값을 예측하거나 범주형 결과를 예측 했다. (데이터 안에 있는 정답이 종속변수이다.)
종속변수의 관측값, 이력 데이터가 있기 때문에 독립변수와의 관계를 찾아볼 수 있었다.
이런 학습 방법을 지도 학습 (Supervised Learning)이라고 한다.
세상의 모든 데이터가 답을 담고 있지 않으므로 다음에는 답을 알지 못하는 것을 풀어주는 기법에 대해 알아보도록 하겠다!
'R' 카테고리의 다른 글
| [R Programming] R help 함수 (0) | 2021.06.10 |
|---|---|
| [R Programming] 머신러닝: 군집분석 - K Means (0) | 2021.05.25 |
| [R Programming] 로지스틱 회귀분석 (0) | 2021.05.21 |
| [R Programming] 다중회귀분석: 독립변수가 범주형 데이터 (0) | 2021.05.20 |
| [R Programming] 회귀분석 - 독립변수가 1개인 회귀분석 (0) | 2021.05.19 |



